

 起動方法と使用方法
起動方法と使用方法2024.10.20
INASOFT
/トップ/改行コード変換 ダウンロード/WebHelp/ヘルプトップ
起動方法と使用方法
●起動方法
lclui.exe を実行してください。
インストーラを利用した場合は、デスクトップに作られたショートカットや、スタートメニューの「プログラム→INASOFT→改行コード変換」から起動できます。
●使用方法
起動すると、変換対象のフォルダ名・ファイル名の入力欄と、変換前・変換後文字列の入力欄などを含んだダイアログが表示されます。
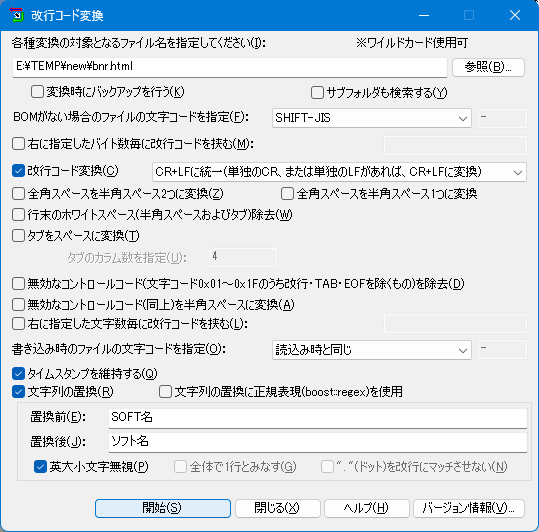
実行画面
- 各種変換の対象となるファイル名を入力してください
変換対象のファイル名を入力します。ファイル名はフルパスで入力してください。ファイル名にはワイルドカード(* および ?)を利用できます。
エクスプローラなどからファイルをドラッグ&ドロップすることもできます。
ファイル中に、C言語の文字列終端記号(文字コード=0x00。Unicodeの場合は0x0000)が含まれていた場合、内部変換処理の妨げとなるため、除去されます。
519文字以内で入力して下さい。 - [参照]ボタン
変換対象のファイル名を、一覧から選択します。
- 変換時にバックアップを行う
ファイルの置換が行われる際、ファイルのバックアップを行います。
バックアップファイルの名前は、元のファイルの名前に.bak をつけたものになります。.bakをつけたファイルがすでに存在する場合は、上書きされます。 - サブフォルダも検索する
変換対象のファイルをサーチするとき、下位のフォルダも検索の対象にします。ここがチェックされると、変換対象のファイル名として入力されたファイル名のうち、フォルダ部分とベースファイル名部分が分離され、フォルダ部分よりも下位の階層のフォルダに対しても、ベースファイル名部分の名称のファイル名での検索が行われます。
例えば、変換対象のファイル名として E:\Temp\a*.txt を指定した場合、E:\Temp下のすべてのフォルダに対して a*.txt にマッチするファイルの検索が行われます。
- 文字コードを指定する
置換前のテキストファイルの文字コードを指定します。
テキストファイルにBOM(ファイル冒頭の文字コード標識)があれば、BOMが優先されますが、BOMがなかった場合は、ここで指定した文字コードが採用されます。
自動判別が指定された場合で判別不能となった場合は、Shift-JISであると仮定して処理を続行します。(自動判別ロジックは完璧ではありません。そのため、置換前ファイルのバックアップは取得しておくことをお勧めします。バックアップの取得の方法は、本ソフトのバックアップ機能を利用しても構いませんし、ユーザーが独自にフォルダごとバックアップするなどの方法を採っても構いません)
自動判別はIEの一部機能を利用して行っていますが、ブラウザで文字化けが起きるのと同様に、この機能も、ある程度の確率で誤判定を起こします。多量のファイルを扱う場合は、確実に数個のファイルで誤判定を起こすことになります。そのため、現時点においてはなるべく「自動判別」は選ばないことをお勧めします。 なお、IBM EBCDIC [Katakana]が利用されている場合は、改行コードはCRしか選べません。「その他 (右にコードページを指定)」を選ぶと、任意のコードページが指定できます。ただし、現在の環境で利用可能なコードページに限ります。変換中のエラーで「パラメーターが間違っています」や「Unicode変換工程でエラーが発生しました。ファイル内容が文字列として解釈できません。」と表示された場合、指定したコードページが間違っている場合の他、指定は正しくても現在の環境では利用できない可能性があります。
- 改行コード変換
変換対象ファイルの改行コードを統一します。次の中から選びます。
- CR+LFに統一(単独のCR、または単独のLFがあれば、CR+LFに変換)
- LFに統一 (単独のCR、またはCR+LFがあれば、LFに変換)
- CRに統一 (単独のLF、またはCR+LFがあれば、CRに変換)
なお、LFのみはUNIX式のテキストファイルの改行コードで、CR+LFはMS-DOS(Windows)式のテキストファイルの改行コードで、CRのみは旧式のMac OS(ver.9まで)のテキストファイルの改行コードです。(※CR='\r'(0x0d), LF='\n'(0x0a))
- 全角スペースを半角スペース2つに変換
テキストファイル中のすべての全角スペースを、半角スペース2つに変換します。
- 全角スペースを半角スペース1つに変換[ver.2.03.00以降]
テキストファイル中のすべての全角スペースを、半角スペース1つに変換します。
なお、「全角スペースを半角スペース2つに変換」と同時に指定した場合、「…2つに変換」の方が先に処理されるため、結果的に全角スペースは2つの半角スペースになります。 - 行末のホワイトスペース(半角スペースおよびTAB)除去
改行コード(CRまたはLF)の直前に半角スペースやTABがあったときに、これらをすべて取り除きます。(※TAB='\t'(0x09))
- タブをスペースに変換
行頭からの距離に応じて、TABを必要な数の半角スペースに変換します。
タブのカラム数は「タブのカラム数を指定」で指定します。99以下で指定して下さい。 - 無効なコントロールコードを除去
文字コード 0x01〜0x1f (ただし、CR,LF,TAB,EOFを除く)を取り除きます。(※EOF=^Z(0x1a)) なお、0x00は処理の前段階で強制的に取り除かれていますので、ここには含まれません。
- 無効なコントロールコードを半角スペースに変換
文字コード 0x01〜0x1f (ただし、CR,LF,TAB,EOFを除く)を半角スペースに変換します。
- 右に指定したバイト数/文字数毎に改行コードを挟む
なんらかの事情で改行コードは入っていないが、ある特定のバイト数あるいは文字数毎に改行が入っていると想定すれば、上手く読めるようなテキストファイルについて、改行コードを挿入します。
「バイト数」の方は、テキストファイル読み込み時に処理されます。
挿入される改行コードは、「改行コード変換」右側のコンボボックスにて選択されている改行コードとなります。※「バイト数」の方で、文字を構成するマルチバイトが破壊される場合(例えばShift-JISの日本語文字を構成する2バイトの間に改行コードが入るようなことになった場合)、その後のUnicode変換動作に支障が生じ、予期せぬ異常が発生する可能性がありますので、ご注意下さい。
- 書き込み時のファイルの文字コードを指定
ファイル書き込み時に、文字コードを変えて書き込みます。
「読み込み時と同じ」を指定した場合は、文字コードは、読み込み時と同じものが採用されます。
なお、ここで文字コードを指定して、書き込み時に「変換エラー」「システムコードへのサイズ不足」「パラメタエラー」などが表示される場合、上の「文字コードを指定する」で指定した文字コードが誤っている場合があります。また、文字コードを自動判別にしていた場合についても、そういったエラーが起きることがあります。「その他 (右にコードページを指定)」については 文字コードを指定する と同様です。
- タイムスタンプを維持する
ファイルの作成日時・最終更新日時(タイムスタンプ)が、元のファイルのままになるようにします。
- 文字列の置換(正規表現の使用有無を選択できます)
ファイル中の文字列の置換を行います。
置換前文字列には正規表現が利用できます。
置換後文字列にはタグ指定が利用できます。
正規表現を使う場合の詳細は「正規表現について」を参照してください。
オプションとして、次のことが指定できます。- 英大小文字無視 …アルファベットの大文字小文字の差を無視します。
- 全体で1行とみなす …ファイル全体を1行としてマッチングを行います。 ^ はファイル先頭、$ はファイル最後にマッチします(正規表現を利用する場合のみ選択可能)。
- "."(ドット)を改行にマッチさせない … . を改行記号とマッチさせません(正規表現を利用する場合のみ選択可能)。
■制限事項
本ソフトウェアはiniファイルへデータを保存している都合上、以下の制限があります。
- ユーザーごとに保存データを分けることはできません。(ただし、Windows Vista以降のリダイレクト機能で自動的に実現されることがあります)。
- 各設定欄の文字列の末尾の半角スペースは、次回起動時に削除されます。
目次へ
※このページは、ソフトウェアに付属のヘルプファイルをWeb用に再構築したものです。大部分に自動変換を施しているため、一部は正しく変換しきれずに表示の乱れている箇所があるかもしれませんが、ご容赦下さい。また、本ドキュメントはアーカイブドキュメントであり、内容は、右上の作成日付の時点のものとなっております。一部、内容が古くなっている箇所があるかと思いますが、あらかじめご了承下さい。
※このページへは、自由にリンクしていただいてかまいません。
■このページに関するご意見をお待ちしております → フィードバックページ