

 正規表現による置換
正規表現による置換Written in Japanese(UTF-8)
2018.10.6
INASOFT
2018.10.6
INASOFT
/トップ/コピペテキスト修飾除去 ダウンロード/WebHelp/ヘルプトップ
正規表現による置換
コピーされたテキストに対して、正規表現やタグ指定による文字列置換が利用できます。これは、boostライブラリのregexを利用したものであるため、boost::regexについてご存じであれば、その方法に従うと考えると簡単です。テキストは内部的にUnicodeで扱われていますので、日本語も使用できます。
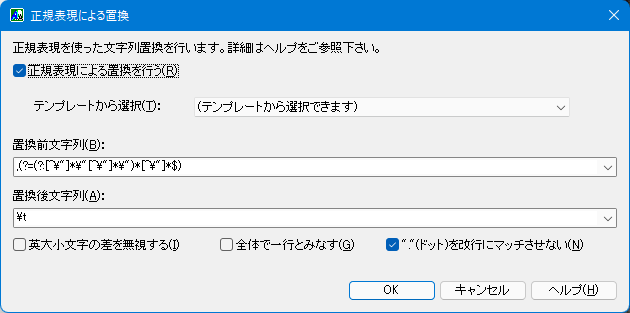
一番上の「正規表現による置換を行う」にチェックを入れることで、置換処理が行われるようになります。
「置換前文字列」には、コピーされたテキスト内でマッチさせるための正規表現を指定して下さい。
「置換後文字列」には、「置換前文字列」でマッチした部分を置換する文字列を指定します。置換前文字列内の特定の部位を表すための「タグ」として $1〜$9 を使用できます。
「英大小文字の差を無視する」にチェックを入れると、アルファベットの大文字・小文字を同一のものとして扱い、マッチ処理が行われます。
「全体で一行とみなす」にチェックを入れると、テキスト全体を1行としてマッチングを行います。 ^ はテキスト先頭、$ はテキスト最後にマッチします。
「"."(ドット)を改行にマッチさせない」にチェックを入れると、. を改行記号とマッチさせません。行単位で置換処理を行いたい場合に便利です。
「テンプレートから選択」は、作者がよく利用する正規表現をまとめたものとなります。一覧から選択すると、「置換前文字列」「置換後文字列」および各チェックボックスが設定されます。
一般的な正規表現の構文は一通り利用できます。代表的な構文を下記に示します。
| 文字 | |
| 記号 | 意味 |
| . (ピリオド1つ) | 任意の一文字 |
| [xyz] | x,y,zのいずれか一文字 |
| [^xyz] | x,y,z以外の一文字 |
| [a-z] | aからzの範囲のいずれか一文字 |
| [^a-z] | aからzの範囲以外の一文字 |
| \w | 単語構成文字 |
| \s | スペース |
| \d | 数字 |
| \l | 英小文字 |
| \u | 英大文字 |
| 繰り返し | |
| 記号 | 意味 |
| x* | xの0個以上の繰り返し |
| x+ | xの1個以上の繰り返し |
| x? | xの0個または1個の出現 |
| x{M,N} | xのM個以上N個以下の繰り返し |
| x{M,} | xのM個以上の繰り返し |
| x{M} | xがM個 |
| x|y | xまたはy |
| ※繰り返しは、通常は最も長いマッチが選択されますが、繰り返し記号の後ろに ? を付けると、最も短いマッチが選択されます。(例: x*?) | |
| 部分式 | |
| 記号 | 意味 |
| (xyz) | 部分式のグループ化 |
| (?:xyz) | 後方参照等が可能でないグループ化 |
| \1〜\9 | 後方参照 |
| 位置指定 | |
| 記号 | 意味 |
| ^ | 行頭 |
| $ | 行末 |
| \< | 単語頭 |
| \> | 単語末 |
| \b | 単語頭または単語末 |
| \B | 単語中 |
| \A | バッファ頭 |
| \z | バッファ末 |
| \Z | バッファ末またはバッファ末の改行 |
| エスケープシーケンス | |
| 記号 | 意味 |
| \| \* \? \+ \( \) \{ \} \[ \] \^ \$ \\ \- | \の後ろの文字の特殊な意味を無視し、通常文字として扱う |
| 置換書式文字列 | |
| 記号 | 意味 |
| $0 | マッチした部分全体 |
| $1〜$9 | 1〜9番目にマッチした部分 |
| ※この正規表現リファレンスは、「いじくるつくーる」のヘルプから抜粋したものとなります。 | |
目次へ
※このページは、ソフトウェアに付属のヘルプファイルをWeb用に再構築したものです。大部分に自動変換を施しているため、一部は正しく変換しきれずに表示の乱れている箇所があるかもしれませんが、ご容赦下さい。また、本ドキュメントはアーカイブドキュメントであり、内容は、右上の作成日付の時点のものとなっております。一部、内容が古くなっている箇所があるかと思いますが、あらかじめご了承下さい。
※このページへは、自由にリンクしていただいてかまいません。
■このページに関するご意見をお待ちしております → フィードバックページ